Task #1193
đóng
Task #1185: Thay disk OS cho cluster proxmox CKEY
Thay Disk Boot KH Ckey
0%
Mô tả
Các Host xảy ra trình trạng treo liên tục => Thay disk boot một số Host để theo dõi tình hình
===========
Chuẩn bị:
- Disk boot cài proxmox 8.2-2
Backup config host
pvesh get /nodes// --output-format json > /root/host-config.jsonBackup config
tar -czf /root/pve-cluster-backup.tar.gz /var/lib/pve-cluster
tar -czf /root/ssh-backup.tar.gz /root/.ssh
tar -czf /root/corosync-backup.tar.gz /etc/corosync
cp /etc/hosts /root/
cp /etc/network/interfaces /root/
- Lưu lại các file config này bằng SCP
===========
Các bước tiến hành, thực hiện theo hướng dẫn: https://projects.longvan.net/projects/lvss/wiki/04-replace-host-loi
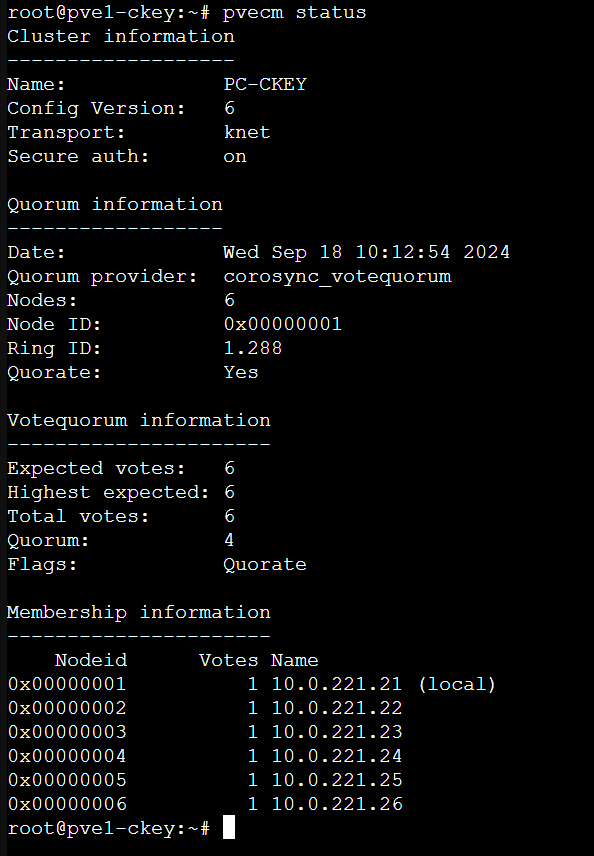
Bước 0: Kiểm tra role của host
Bước 1: Maintenance Ceph
Bước 2: Tiến hành cắm disk và reboot host
Bước 3: Cho boot vào disk OS
Bước 4: Restore config
Restore /etc/hosts/:
cp /root/hosts /etc/hostsRestore /etc/network/interfaces:
cp /root/interfaces /etc/network/interfacesRestore the files in /root/.ssh/:
cd / && tar -xzf /root/ssh-backup.tar.gzreplace /var/lib/pve-cluster/ :
rm -rf /var/lib/pve-cluster
cd / && tar -xzf /root/pve-cluster-backup.tar.gzReplace /etc/corosync/ :
rm -rf /etc/corosync
cd / && tar -xzf /root/corosync-backup.tar.gzStart pve-cluster:
systemctl start pve-cluster.serviceStart the rest of the services:
systemctl start pvestatd.service
systemctl start pvedaemon.service
===============
Các lỗi có thể xảy ra:
- Thiếu dữ liệu hoặc backup không đầy đủ: Đảm bảo rằng quy trình backup đã được thiết lập
- Không thể truy cập hoặc khôi phục từ tệp backup: Đảm bảo rằng tệp backup được lưu trữ ở một nơi an toàn và có thể truy cập được khi cần thiết.
=============
- Thứ tự các host sẽ thay: ưu tiên thực hiện node 5 trước ( bị treo nhiều lần) để theo dõi tinhfh trạng node 6 node 4 node 2 node 1
==============
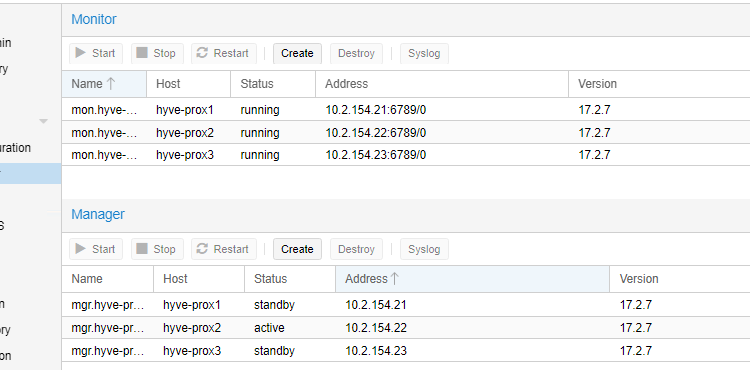
Lưu ý: Sau khi đổi disk OS cho node có role là ceph-mon/ceph-mgr
- Bổ sung host với role ceph mon/mgr nhằm tránh rủi ro toàn bộ các service mon/mgr bị down thì ta tăng số lượng server chạy các role đó lên.
- Sau khi replace node có role MON/MGR thì phải thực hiện remove khỏi file ceph config (/var/lib/ceph/) và tiến hành readd lại service mon/mgr cho node đó.
- Không backup /var/lib/ceph/ vì dữ liệu thay đổi liên tục nếu restore lại thì sẽ bất đồng bộ với các node khác đang chạy làm VM bị lỗi.
==============
Lưu ý: trường hợp replace disk OS lỗi. Host không hoạt động bình thường như cũ tiến hành kiểm tra như sau:
- Kiểm tra thông báo lỗi: Kiểm tra log của Proxmox để xem có thông báo lỗi cụ thể nào xuất hiện khi khởi động hệ thống.
- Kiểm tra service Proxmox:pveproxy, pvedaemon, pvestatd để đảm bảo chúng đang hoạt động đúng.
- Kiểm tra các bản backup
Tập tin
{kind=link}
{kind=link}