Actions
Bug #622
đóng
Reboot Proxmox Cụm CMC Q9
Bắt đầu:
01-04-2024
Hết hạn:
Tiến độ:
100%
Thời gian ước lượng:
Mô tả
Reboot toàn bộ host trong cluster ¶
Hiện trạng:
- Uptime của các host quá lâu
======================================
Quy trình reboot
- Bước 1: Kiểm tra ceph storage
- Bước 2: Set maintenance ceph noout,nobackfill,noscrube,nodeep-scrub,norebalance,norecover
- Bước 3: Migrate các VM trên host qua node khác. VM trong HA cũng migrate qua node khác
- Bước 4: Kiểm tra lại các OSD đã up lại, bỏ maintenance ceph, trạng thái đã OK thì mới làm tiếp host khác
Lưu ý: cân bằng resource RAM/CPU của các node khi migrate VM
=======================================
Thứ tự reboot host
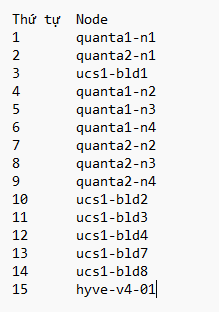
======================================
Rủi ro có thể xảy ra:
- Disk OS failed
- Lõi phần cứng ( ram, cpu, network adapter)
- OSD down
- Disconnect Host
- Thời gian update :
- Thông báo: khách hàng, các team liên quan
- Phân loại các host và thứ tự reboot các host
- Network chập chờn: lỗi HA, reboot toàn bộ cluster
===========================
Các biện pháp khắc phục:
- Chuẩn bị trước disk boot và USB boot OS
- Check thông số cũng như model ram, cpu để chuẩn bị trước
- Kiểm tra status của OSD trong ceph.
- Backup file network, truy cập IPMI của host để kiểm tra.
- Kiểm tra các bản vá lỗi, ceph version để update và reboot chung"
- Phạm vi ảnh hưởng: thống kê dịch vụ khách hàng theo pool
- Gửi thông báo cho khách hàng"
==========================
File cập nhật thông tin chi tiết:
https://docs.google.com/spreadsheets/d/1MWVT91_zm0CpSAA3xU8AunrzVxVK41gnF26NE1SZHwQ/edit#gid=1703051663
Tập tin
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Tập tin clipboard-202404071242-v8vgi.png clipboard-202404071242-v8vgi.png được thêm
- Mô tả cập nhật (Sự khác nhau)
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Mô tả cập nhật (Sự khác nhau)
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Mô tả cập nhật (Sự khác nhau)
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Mô tả cập nhật (Sự khác nhau)
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Mô tả cập nhật (Sự khác nhau)
Cập nhật bởi Thanh Tâm Nguyễn cách đây khoảng 1 năm
- Mô tả cập nhật (Sự khác nhau)
Actions